07.02.2007 -- added SCTP plot
06.30.2007 -- added plot with TIPC recv_stream patch
10.26.2007 -- added missing UDP/SOCK_DGRAM plot
This page lists results of a few tests with TIPC 1.7.3.
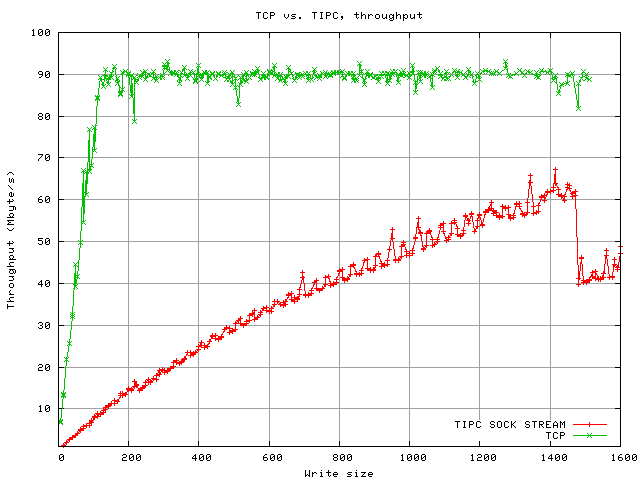
All these tests were made using Linux 2.6.20 on GB-Ethernet hardware. The sending machine is an AMD Athlon 64 X2 (dual core) 4600+, the receiver is a Intel Xeon (2.8 GHz). The sending machine uses a tg3 network interface, the receiver has an Intel e1000. Both interfaces support rx/tx checksumming, scatter/gather and TCP segmentation offloading (all were left enabled). The machines were directly connected, i.e. no switch. The unit is Megabytes per second.
Network throughput for write sizes of up to 2000 byte. The TCP Nagle algorithm was not disbled. The significant drop with TIPC occurs when the write size exceeds 1476 bytes, at which point fragmentation has to be performed (the MTU is 1500 byte, a TIPC header has 24 bytes in this test setup). For writes of 1480 bytes, this creates packets with payloads of 1476 and 4 bytes, thus doubling the amount of packets transferred.
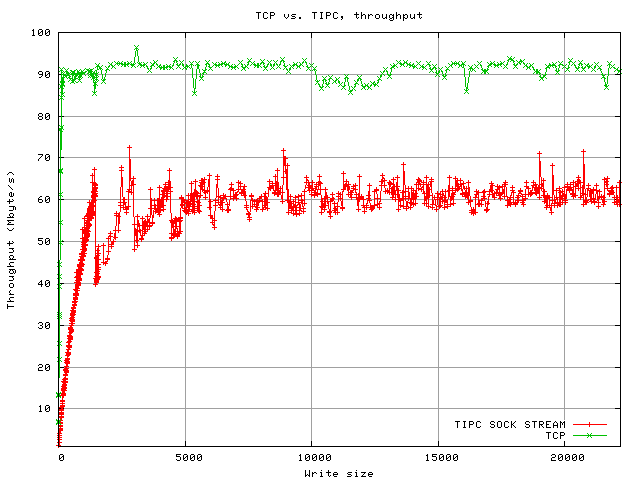
Network Throughput for write sizes of up to 22000 byte. During this test it was observed that the receiving machine was under full cpu load - this was not expected. Upon closer examination, it was found that every read call only returned 1476 bytes of data, i.e. one fragment (1476 byte payload + 24 byte header size equals the link MTU used). After consulting the relevant TIPC stream receiving code the test program was modified to use recv and the MSG_WAITALL flag. This halved CPU load on the receiving end and dramatically improved througput.
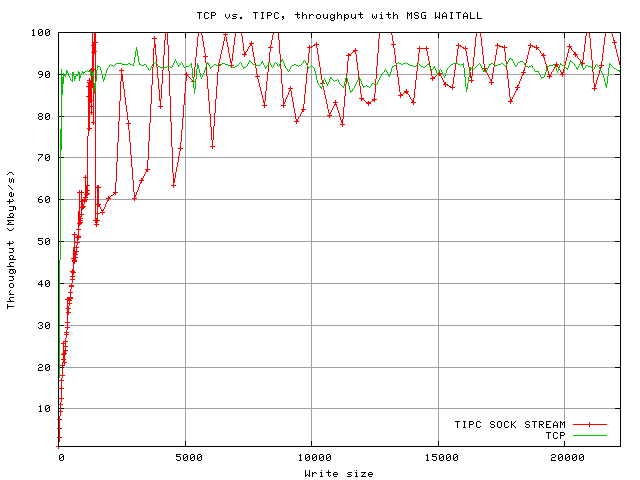
The TCP tests were run multiple times, the plot shows the average values. Due to time constraints, the tests were not repeated with TIPC; thus some values are little bit more off than expected. See below for values obtained with a kernel-side modification that results in similar behaviour.
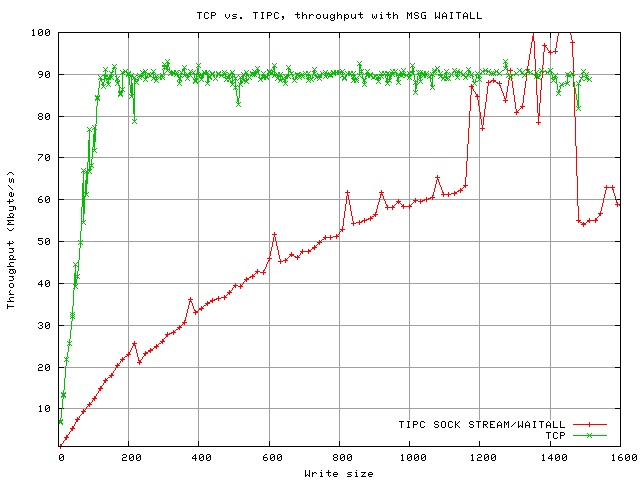
When writing small chunks to the socket, TCP is still at an advantage due to the nagle algorithm, but the practical impact is small; applications that write data in large volumes do not write in tiny chunks anyway. Those that do usually care about latency rather than raw network throughput and thus normally disable the nagle algorithm anyway. This patch for TIPC has the same effect if the application is receiving data at high speed:
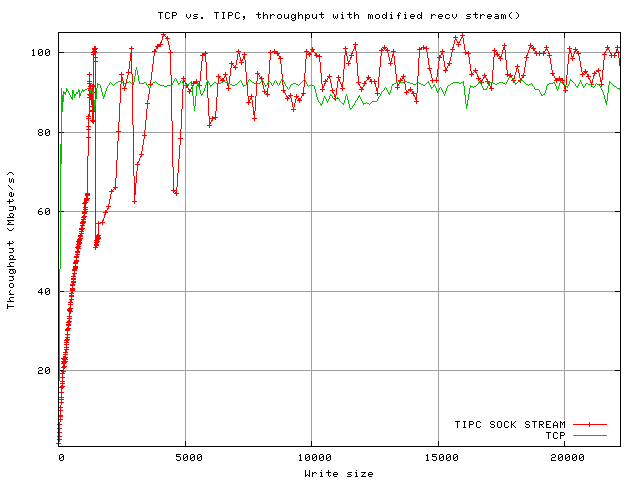
Again one can see minor speed decrease when the fragmentation is not ideal, e.g. a 22080 byte chunk is split into 14 packets with 1476 byte of payload each, plus one fragment with 1416 of payload. A 22208 byte chunk creates 15 1476 byte fragments and a fragment with only 68 bytes (this depends on the bearer MTU and the header size. During this test, the MTU was 1500 bytes and a 24 byte TIPC header was added). This results in slightly decreased throughput (about 6 MBye/s lower).
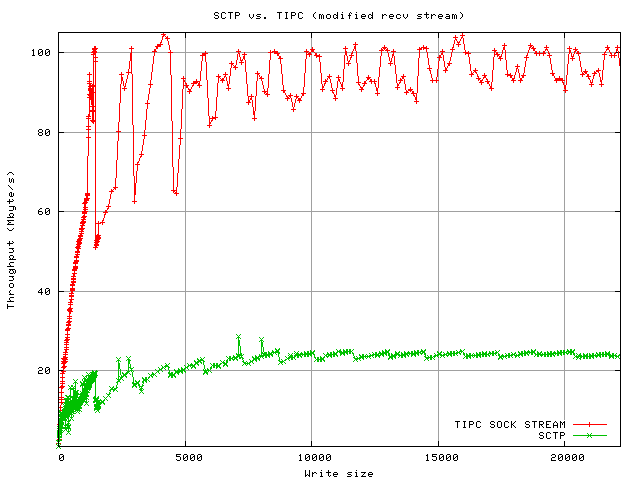
SCTP was very slow when compared to TIPC. The receiving end was under 100% CPU load (sys). The cause has not been investigated.
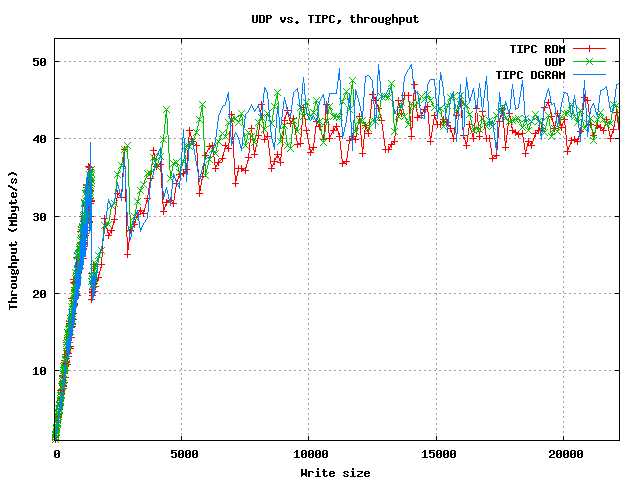
UDP vs. TIPCs RDM and DGRAM sockets. Throughput was measured on the receiving in order to avoid bias due to packet loss.